
Taming Background Noise in Real-Time Voice Agents

The Problem
We run an outbound voice agent built on Deepgram's Voice Agent API - it calls patients, delivers messages, and handles follow-up questions in real time over Twilio. The system worked well in quiet environments. But the moment there was any background noise - a fan, a TV, traffic, someone typing - the agent would stop mid-sentence.
The root cause: Deepgram's internal Voice Activity Detector (VAD) was triggering a UserStartedSpeaking event on background noise. Our code, following Deepgram's documented guidance, immediately cleared Twilio's audio buffer on every such event. The result? A brief noise blip would cut off the agent, create an awkward silence, and the caller would hear nothing.
This made the agent unusable in real-world conditions where calls happen in living rooms, offices, and busy streets - not soundproofed studios.
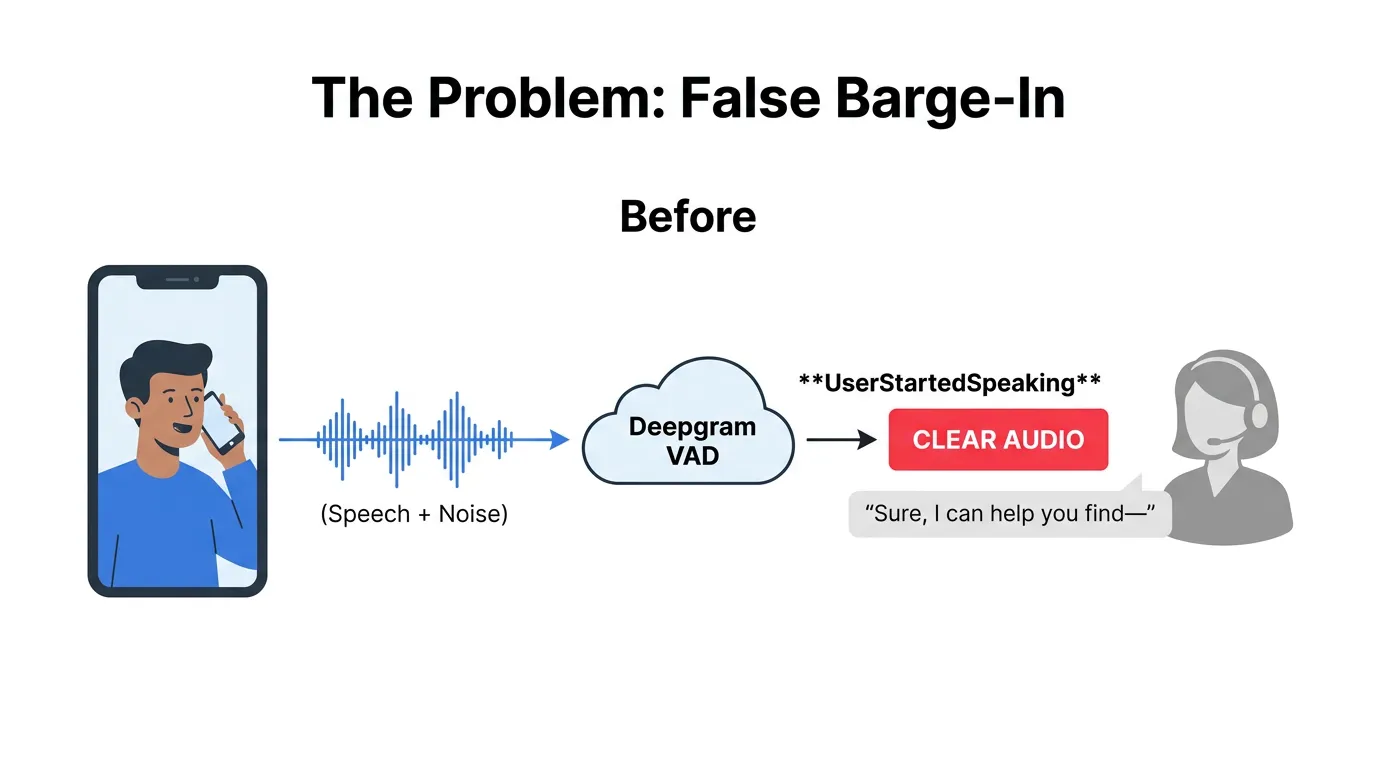
Figure 1: Background noise triggers false barge-in, cutting off the agent mid-sentence.
Why This Is Hard to Fix at the Config Level
Our first instinct was to tune Deepgram's settings. We tried adding endpointing and utterance_end_ms to the listen provider configuration:
{
"listen": {
"provider": {
"type": "deepgram",
"model": "nova-3",
"endpointing": 480,
"utterance_end_ms": 1500
}
}
}
Deepgram rejected this - the Voice Agent API does not expose VAD sensitivity, endpointing, or utterance detection settings in the listen.provider block. The only documented fields are type, model, version, language, keyterms, and smart_format.
The UserStartedSpeaking event is fired by Deepgram's internal VAD, and there is no knob to adjust its sensitivity through the Settings message. This is a known limitation. So we had to solve this at the application layer.
The Solution: Two Layers of Protection
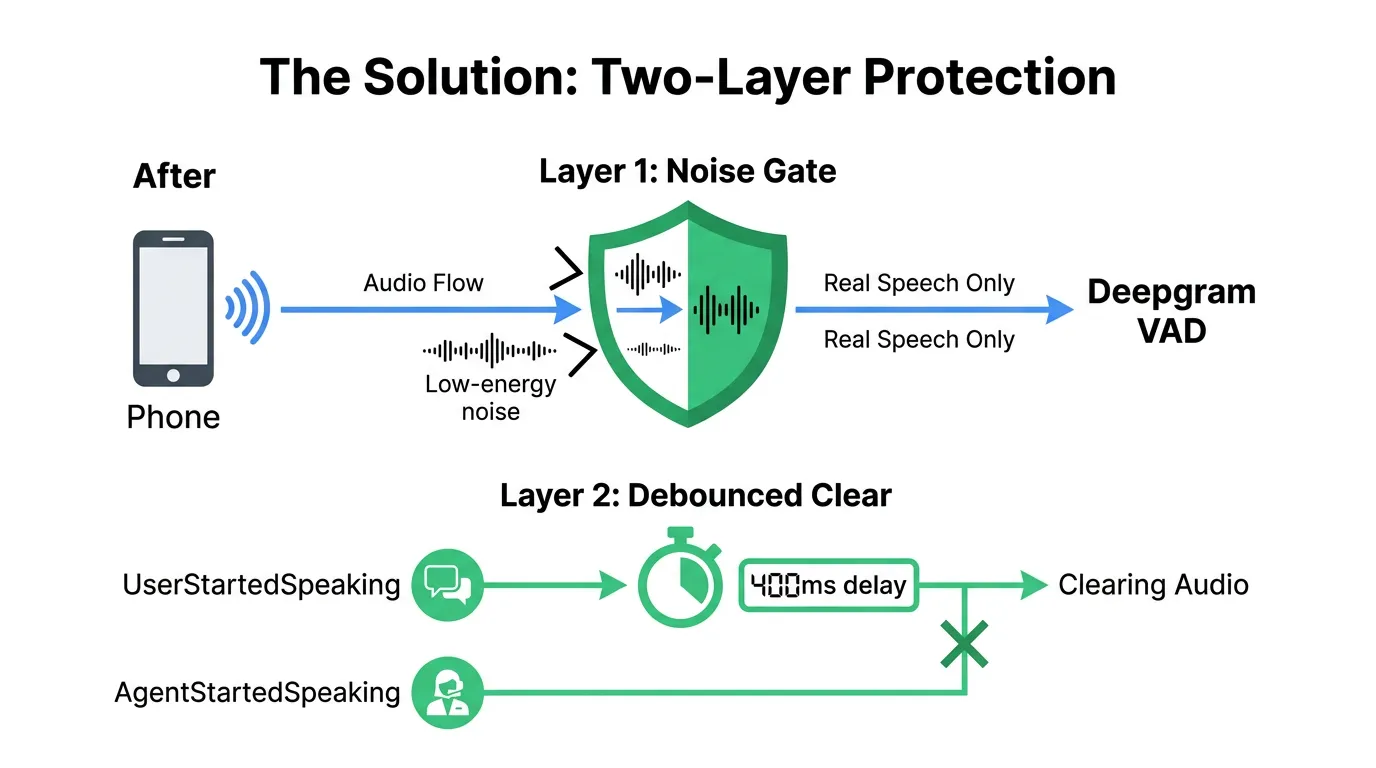
Figure 2: Two-layer protection - noise gate filters audio before Deepgram, debounce prevents false clears.
Layer 1: Audio Noise Gate
The most impactful change was preventing Deepgram from ever "hearing" the noise in the first place.
Our audio pipeline receives raw mu-law encoded audio from Twilio (8-bit, one byte per sample, 8 kHz). In mu-law encoding, silence sits near byte values 0xFF (255) or 0x7F (127). The further a sample deviates from these values, the louder the signal.
We added a noise gate that measures the average energy of each audio chunk before sending it to Deepgram. If the energy is below a threshold, the chunk is replaced with silence:
_MULAW_SILENCE_BYTE = 0xFF
_NOISE_GATE_THRESHOLD = int(os.getenv("NOISE_GATE_THRESHOLD", "12"))
def _apply_noise_gate(chunk, threshold=_NOISE_GATE_THRESHOLD):
if not chunk:
return chunk
energy = sum(
min(abs(b - 0xFF), abs(b - 0x7F)) for b in chunk
) / len(chunk)
if energy < threshold:
return bytes([_MULAW_SILENCE_BYTE]) * len(chunk)
return chunk
This runs on every 400 ms audio chunk (3,200 bytes at 8 kHz mu-law) before it enters the queue to Deepgram. Background noise like fans, ambient chatter, and keyboard clicks typically produce an average energy of 2-8. Normal speech starts around 15-30. A threshold of 12 cleanly separates the two.
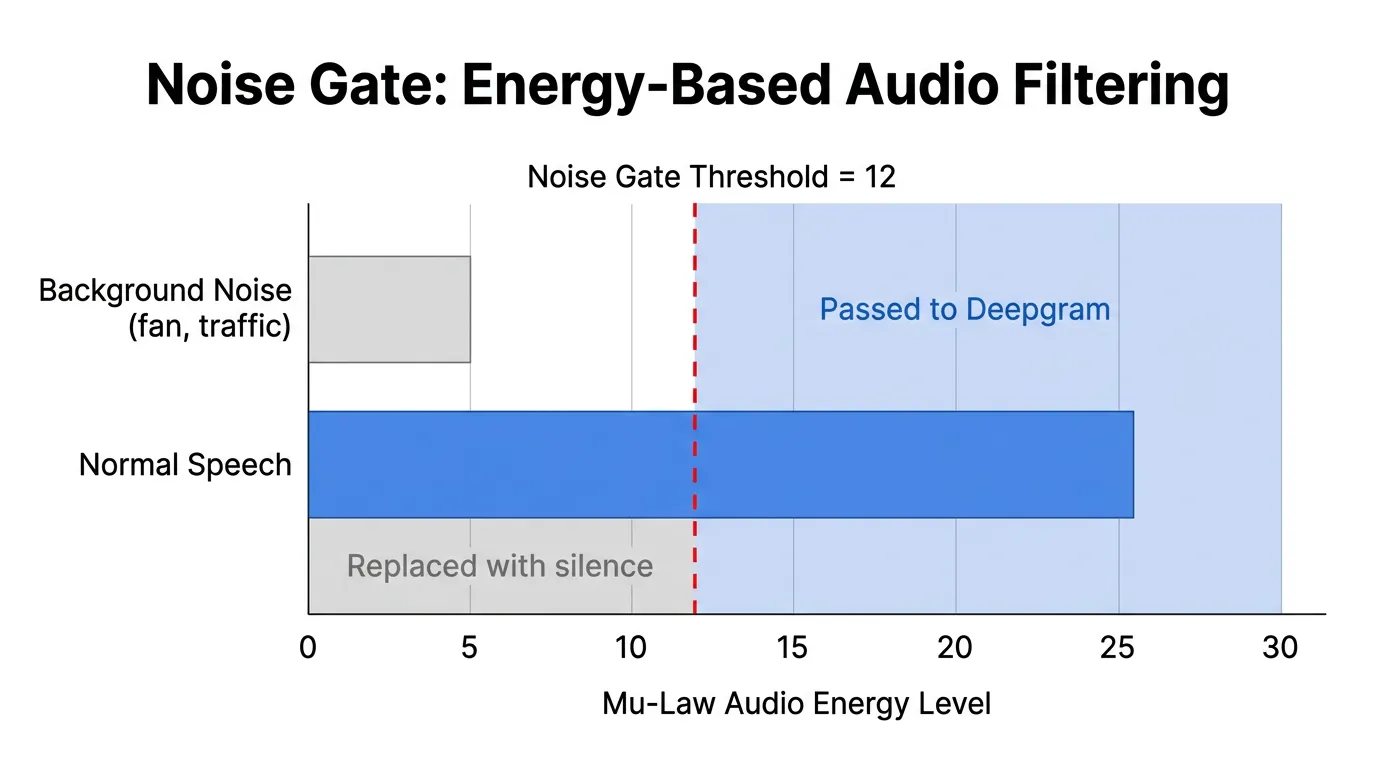
Figure 3: Energy-based noise gate - background noise falls below the threshold and is replaced with silence.
Layer 2: Debounced Barge-In
Even with the noise gate, some borderline audio might still slip through and trigger UserStartedSpeaking. Our second layer addresses the response to that event.
Previously, the code immediately cleared Twilio's audio buffer on every UserStartedSpeaking event. Now, the clear is delayed by 400 ms. If the agent resumes speaking (AgentStartedSpeaking) before the delay expires, the clear is cancelled and the buffered audio keeps playing:
_pending_clear = None
_CLEAR_DELAY = float(os.getenv("BARGE_IN_DELAY_MS", "400")) / 1000.0
async def _delayed_clear(sid):
await asyncio.sleep(_CLEAR_DELAY)
await twilio_ws.send(
json.dumps({"event": "clear", "streamSid": sid})
)
# On UserStartedSpeaking - schedule delayed clear
if msg_type == "UserStartedSpeaking":
if _pending_clear and not _pending_clear.done():
_pending_clear.cancel()
_pending_clear = asyncio.ensure_future(
_delayed_clear(streamsid)
)
# On AgentStartedSpeaking - cancel the clear
if msg_type == "AgentStartedSpeaking":
if _pending_clear and not _pending_clear.done():
_pending_clear.cancel()
This means brief noise triggers no longer cut off the agent. If the user genuinely starts speaking, the 400 ms delay is imperceptible - but it's enough to filter out false triggers.
How the Two Layers Work Together
| Scenario | Noise Gate | Debounced Clear | Result |
|---|---|---|---|
| Background fan running | Replaced with silence | Never triggered | Agent speaks uninterrupted |
| Brief cough or door slam | May pass through | Clear scheduled, then cancelled | Agent continues speaking |
| User actually starts talking | Passes through (high energy) | Clear fires after 400 ms | Agent stops, listens to user |
Tuning Guide
After deploying, you may need to adjust the thresholds based on your environment. Both values can be set as environment variables - no code changes or redeployment needed.
| Symptom | Fix |
|---|---|
| Agent still interrupts on noise | Increase NOISE_GATE_THRESHOLD (try 15-20) |
| Quiet speech is being filtered out | Decrease NOISE_GATE_THRESHOLD (try 8-10) |
| Agent takes too long to respond | Decrease BARGE_IN_DELAY_MS (try 200-300) |
| Agent still cuts off in noisy environments | Increase BARGE_IN_DELAY_MS (try 500-600) |
Key Takeaways
- Voice Agent APIs don't always expose VAD tuning. Deepgram's Voice Agent API manages VAD internally with no configuration options. If your provider has the same limitation, you need application-layer solutions.
- Filter before you send. A simple energy-based noise gate on the raw audio is more effective than any post-detection logic. If the VAD never hears the noise, it never fires a false event.
- Debounce, don't block. Completely disabling barge-in makes the agent feel robotic. A short delay preserves natural interruption while filtering out noise blips.
- Make it configurable. Audio environments vary wildly - a hospital lobby is different from a quiet office. Environment variables let you tune per deployment without touching code.
Built with Deepgram Voice Agent API, Twilio Media Streams, and Cartesia Sonic-3 TTS.
Related articles
Jun 5, 2026·6 min read
How We Automated WhatsApp Onboarding for Every Client (Without Touching Meta's Dashboard)
A walkthrough of how we used Meta's Embedded Signup and the WhatsApp Cloud API to let clients self-onboard their WhatsApp number — entirely through code.
May 22, 2026·7 min read
Optometry Patient Engagement Vendors in Dallas: 2026 Vendor Comparison
Compare the top optometry patient engagement vendors for Dallas, TX practices in 2026 — Starfish Health vs. DoctorConnect, Adit, RevEngage, and Weave.
May 2, 2026·9 min read
Building a Production-Grade Data Pipeline
ETL pipeline: JSON extraction, Supabase raw tables, dbt transforms, production UPSERTs—manifests, queues, idempotency, and failure modes we hit in production.